前置き
AIを使っての画像認識による物体検出は、自動運転・セキュリティ対策・顧客分析・異常検知・画像診断など様々な分野で利用されています。
AIの基礎に触れてみるということで、YOLOv5を使ってAIを体験してみました。
ちょうど社内サーバーの更新時期と重なったので、新品のパソコンでの環境で作業することができましたので、学習モデルの作成も苦もなくこなせるのではないかと思います。
今回は、Nゲージの鉄道模型を使って車両の種類の学習をおこない、車両の種類を認識・検出させてみたいとおもいます。

実は、Corei5-2400(グラボ無し)という骨董品みたいなマシンが転がっていたので、こいつにUbuntu環境を作成して実行したのですが、PyTourchでの学習を200Epoch(回)繰り返すと36時間もかかってしまいました。
今回用意した新環境では、約18分で終了しました。
実行環境
CPU : AMD Ryzen 7 5700X BOX
メモリー:64GB (32GB x 2)
グラフィックボード:MSI GeForce RTX 3060 12GB
マザーボード:MSI MAG B550 TOMAHAWK
SSD: ADATA M.2 2TB
OS: Ubuntu 22.04
現時点でコスパの優れているAMD Ryzen7 5700Xを中心に組んでいるので、程々の性能ですが業務使用サーバーとしては充分な性能です。

YOLOv5について
YOLOv5は、YOLOv3のPyTorch版実装を作成したGlenn Jocher氏(Ultralytics社)が2020年6月に発表したバージョンです。
2023年1月には、後継バージョンにYOLOv8が発表されています。
ライセンスはAGPL-3.0 (GNU Affero General Public License v3.0)となっています。
GitHub https://github.com/ultralytics/yolov5
YOLOの系譜
- YOLOv1 ※Joseph Redmon
- YOLOv2
- YOLOv3 ※Joseph Redmon, Ali Farhadi
- YOLOv4 ※Alexey Bochkovskiy
- YOLOv7
- YOLOv5 ※Glenn Jocher(Ultralytics社)
- YOLOv8
- YOLOv4 ※Alexey Bochkovskiy
- YOLOv3 ※Joseph Redmon, Ali Farhadi
- YOLOv2
- YOLOv6 ※Meituan Technical Team
| 作者 | バージョン | バージョン |
| Alexey Bochkovskiy | YOLOv4 (2020年4月) https://github.com/AlexeyAB/darknet | YOLOv7 (2022年7月) https://github.com/WongKinYiu/yolov7 |
| Glenn Jocher (Ultralytics社) | YOLOv5 (2020年6月) https://github.com/ultralytics/yolov5 | YOLOv8 (2023年1月) https://github.com/ultralytics/ultralytics |
| Meituan Technical Team | YOLOv6 (2022年6月) https://github.com/meituan/YOLOv6 |
サンプルコード
YOLOv5には以下のサンプルコードがあります。
これらの、サンプルコードを使うことにより、簡単にAIの技術に触れることができます。
- train.py
- 独自に用意したデータセットから、独自の学習モデルを作成することができます。
- detect.py
- 学習モデルを使って様々なソース(ウェブカメラ・静止画jpg・動画mp4・スクリーンショット・YouTube・ストリーム動画)から推論を実行し、物体検知を行い結果を保存します。
CUDA Toolkitのインストール
今回用意したPCには、グラフィックボードに GeForce RTX 3060 があるので、PyTorchによる機械学習時にGPUを使って処理能力をあげるために、NVIDIAが提供しているGPU向けの汎用並列コンピューティング環境であるCUDAをインストールしておきます。
CUDAのサイトにインストール条件を入力します。
https://developer.nvidia.com/cuda-downloads

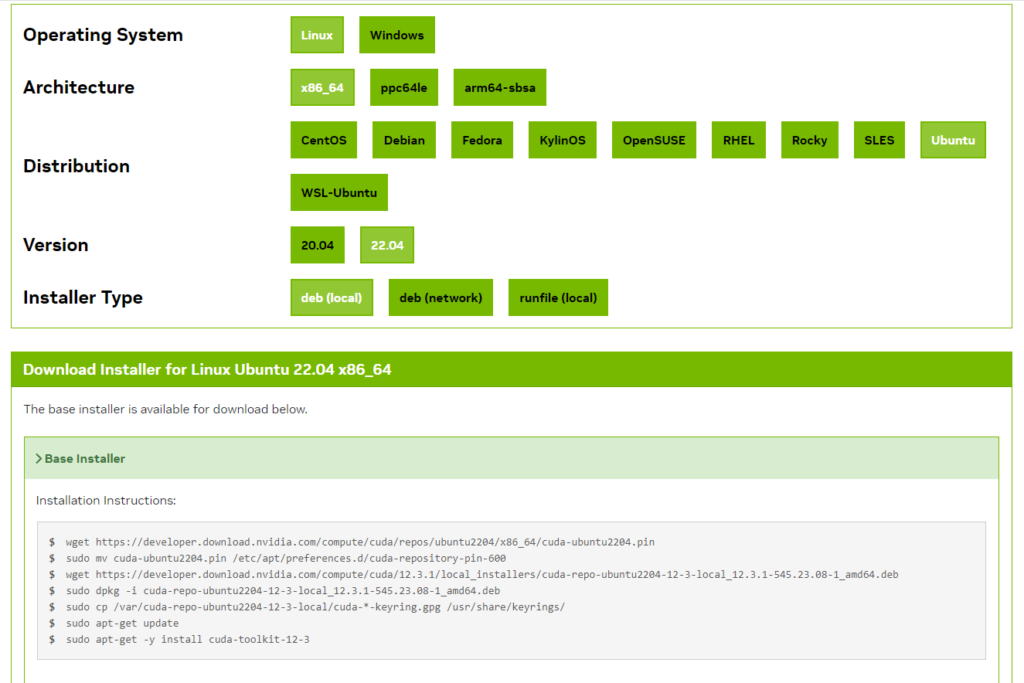
Operating System : Linux
Architecture : x86_64
Distribution : Ubuntu
Version : 22.04
Installer Type : deb(local)
Installation Instructions にインストール方法が生成されます。
今回の場合は以下のように生成されました。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.3.1/local_installers/cuda-repo-ubuntu2204-12-3-local_12.3.1-545.23.08-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-3-local_12.3.1-545.23.08-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-3-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-3インストール後 .bashrc に CUDA のパスを追加
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"PyTorchのインストール
PyTorchとは
Facebookが開発を主導したPython向けの機械学習ライブラリです。
インストール
PyTorchのサイトにインストール条件を入力します。
https://pytorch.org/get-started/locally/

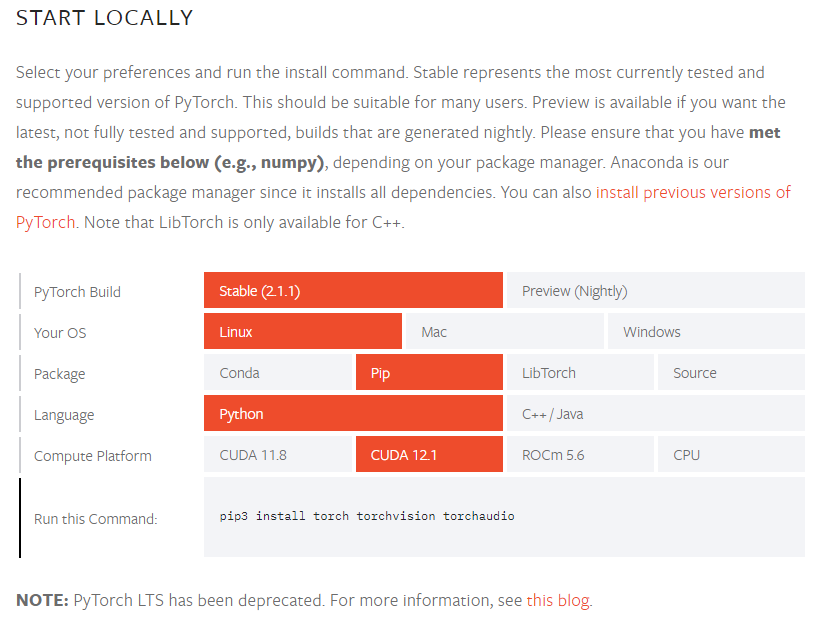
PyTorch Build : Stable (2.1.1)
Your OS : Linux
Package : Pip
Language : Python
Compute Platform : CUDA 12.1
Run this Command に、インストールコマンドが生成されます。
pip3 install torch torchvision torchaudio画像処理ライブラリ(OpenCV)のインストール
pip3 install opencv-python学習済みモデル YOLOv5 のインストール
YOLOv5は以下のページで公開されています。
GitHubのリポジトリをダウンロード
git clone https://github.com/ultralytics/yolov5YOLOv5を使用するために必要なライブラリのリストをインストール
cd yolov5
pip3 install -r requirements.txtサンプルコードからの動作確認
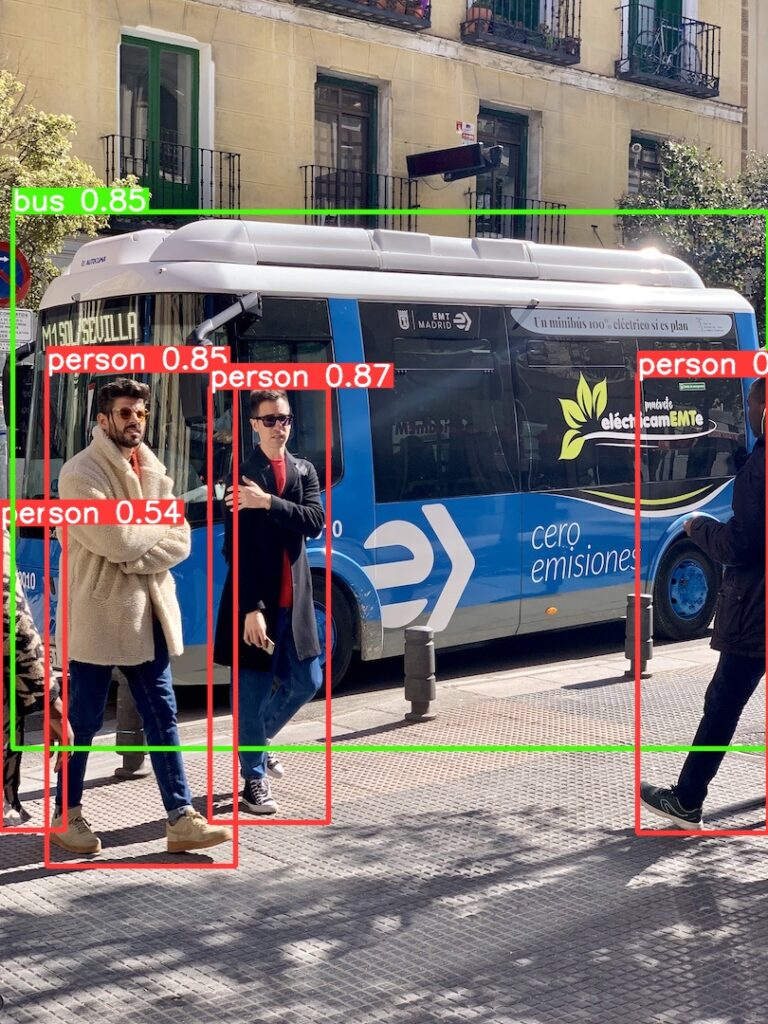
python3 detect.py実行すると yolov5/runs/detect/exp フォルダに学習データから画像認識した結果が作成されます。
- ホーム
- yolov5
- runs
- detect
- exp ※ 実行結果
- detect
- data
- images ※ 元データ
- runs
- yolov5
人物やバスが認識されています。
元データは yolov5/data/images にあります。

Nゲージ鉄道模型を学習して、車両の車種を認識させる
取り敢えず物体検出は動作したので、独自に学習データを作成して画像を認識させてみたいと思います。
こちらも参考にしてください。
学習用データを用意する
学習させるNゲージ鉄道模型は次の5種類です。

右上から時計回りで、EF210-100形・コキ107形フレイトライナー・コキ107形国際海上コンテナ・コキ104形ヤマト運輸コンテナ・タキ1000形(日本石油輸送・米タン)の5種類です。
色々な方向から各車両を撮影して学習用データを作成します。

このように色々な方向から撮影しました。
今回用意した学習用データは262枚の画像を用意しました。
この枚数が多いのか少ないのかはわかりませんが、結果は良い検出率だったのでよしとします。
学習用データのアノテーション(ラベル付け)
用意した学習用データだけでは何を学習して良いのかわかりません。
そこで、学習用データの画像にアノテーション(ラベル付け)をして、画像の中にある検出する被写体を指定していきます。
labelimg
今回、アノテーションには labelImg というアプリケーションを使いました。
labelImgは画像に写っている特定の被写体の座標とラベルデータを作成して、学習モデル作成に必要なデータを作成します。
labelImgのインストール
今回は、GitHubのレポジトリをクローンしてインストールしました。
git clone https://github.com/heartexlabs/labelImg.git必要なモジュールのインストール
cd labelImg
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3labelImgの起動
python3 ./labelImg/labelImg.pyラベルの定義
今回は、EF210-100形・コキ107形フレイトライナー・コキ107形国際海上コンテナ・コキ104形ヤマト運輸コンテナ・タキ1000形(日本石油輸送・米タン)の5種類の被写体にラベルをつけるので、あらかじめラベルをテキストデータで作成しておくとスムーズにラベル付けすることができます。
./labelImg/data/predefined_classes.txt に以下のようにラベルを記述しておきます。
EF210-100
KOKI107-FreightLiner
KOKI107-IntermodalContainer
KOKI104-YAMATO
TAKI1000-NihonSekiyu指定されたラベルが選択することができ入力ミスを減らすことができます。
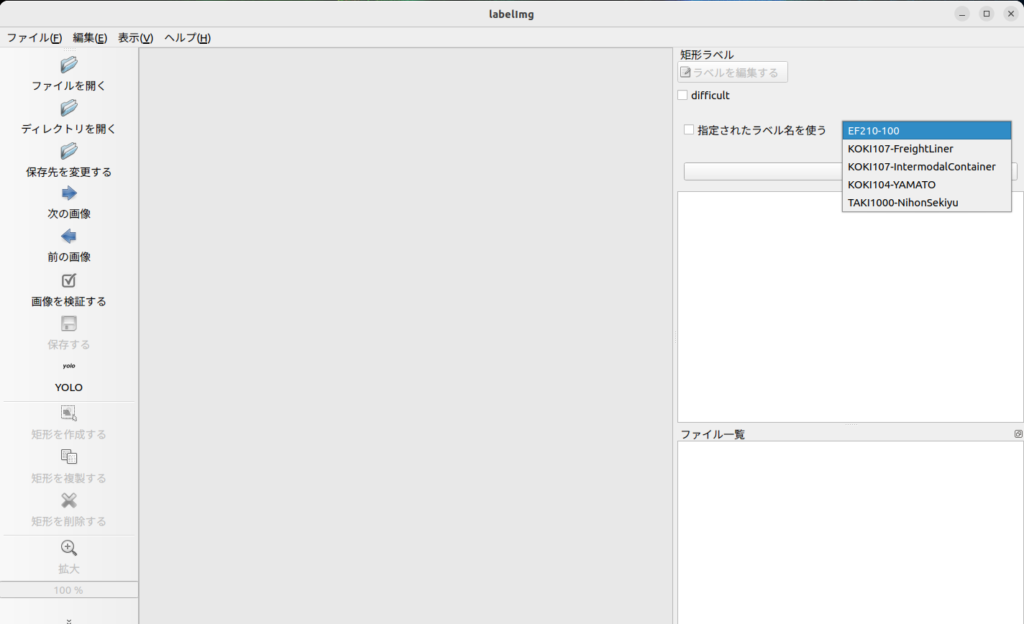
アノテーションデータを作成する。
「ディレクトリを開く」で、学習用データの入っているディレクトリを開きます。
ディレクトリ内のjpgファイルが表示されます。
「次の画像」・「前の画像」で画像を遷移することができます。
画像内に写っている被写体を「矩形を作成する」で矩形で囲んで、ラベルを指定します。
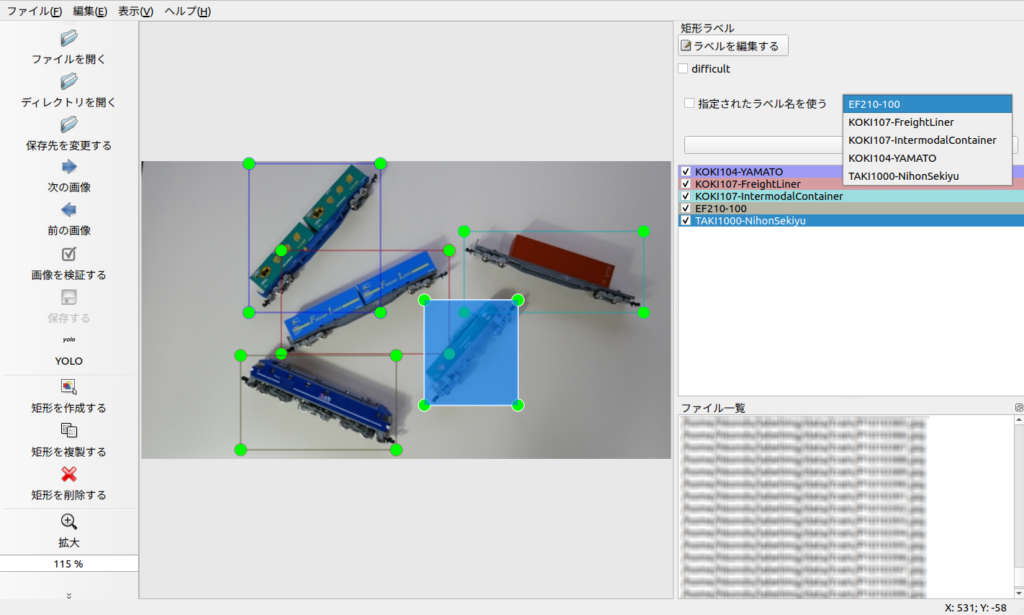
ラベルを付け終わったら保存するデータフォーマットを「YOLO」にして「保存する」をクリックします。
「画像のファイル名.txt」でアノテーションデータが作成されます。
- 【例】
- P1010387.jpg — 画像ファイル
- P1010387.txt — アノテーションデータ
3 0.327344 0.258333 0.248438 0.500000
1 0.422656 0.473611 0.317188 0.347222
2 0.778906 0.372222 0.339062 0.272222
0 0.334375 0.811111 0.293750 0.316667
4 0.622656 0.643056 0.176563 0.352778ラベルの番号(predefined_classes.txt に記述した順番号 ※1行目は0開始の3なので「KOKI104-YAMATO」を指す)と、矩形の画像上の座標位置を示します。
学習用データを使ってPyTorchでの学習
ラベル付の終わった学習用データを使って、PyTorchにより独自の学習モデルを作成します。
学習用データの配置
ラベル付の終わった学習用データを任意のディレクトリにコピーします。
検証用データは学習用データから2割程度をランダムに選択してコピーします。
今回は yolov5/data ディレクトリに作成しました。
- ホーム
- yolov5
- data
- train — 学習用データ
- image — 学習用データ 画像ファイル (.jpg)
- labels — 学習用データ アノテーションデータ (.txt)
- valid — 検証用データ
- image — 検証用データ 画像ファイル (.jpg)
- labels — 検証用データ アノテーションデータ (.txt)
- data.yaml — 学習パラメータファイル
- train — 学習用データ
- data
- yolov5
学習用データは学習するための元データとなります。
検証用データは学習の習熟率を計るために使われます。
- 学習用データで学習し、学習モデルに反映させる
- 学習モデルを使って検証用データで物体検出をおこない、アノテーションデータとの差異で評価をおこない習熟率を計る
学習を反復して習熟率を高める。
学習を何回反復するかを決定するのが epochs オプションです。
学習パラメータファイルの作成
YOLOv5サンプルプログラムtrain.pyは、学習パラメータファイルから実行環境を指定します。
yolov5/data 下に学習パラメータファイルを data.yaml 作成しました。
train: data/train/images
val: data/valid/images
nc: 5
names: [ 'EF210-100','KOKI107-FL','KOKI107-ICon','KOKI104-YAMATO','TAKI1000-NiSeki']パラメータファイルの内容説明
- train — 学習用データディレクトリ
- val — 検証用データディレクトリ
- nc — 学習要素数
- names — 学習要素名
事前トレーニング済モデルの選択
事前トレーニング済モデルには、YOLOv5n / YOLOv5s / YOLOv5m / YOLOv5l / YOLOv5x の5段階のモデルが用意されています。
YOLOv5n < YOLOv5s < YOLOv5m < YOLOv5l < YOLOv5x の順で検出精度が高くなりますが、実行速度が遅くなり必要メモリ・学習モデルも大きくなります。
他に学習モデルサイズが1280pxの YOLOv5n6 / YOLOv5s6 / YOLOv5m6 / YOLOv5l6 / YOLOv5x6 のモデルも用意されています。
事前トレーニング済モデルは、0から80までのクラスを学習しています。
もし、既存の学習モデルの追加で学習したい場合は yolov5/data/coco.yaml を参考にして、クラスをコピーして既存クラスの後に追加するクラスを入れます。アノテーション時からクラスを統一できるようにしておきます。
事前トレーニングモデルは以下からもダウンロードできます。
GitHubにも詳しいデータが記載されています。
よくサンプルなどで目にするのは、YOLOv5sを選択するのを奨めることが多いですが、今回は速度が少々遅く学習モデルが大きくなっても検知精度をあげたいのでYOLOv5mを選択します。
YOLOv5のREADME.mdに学習結果の違いがグラフにて示されていました。
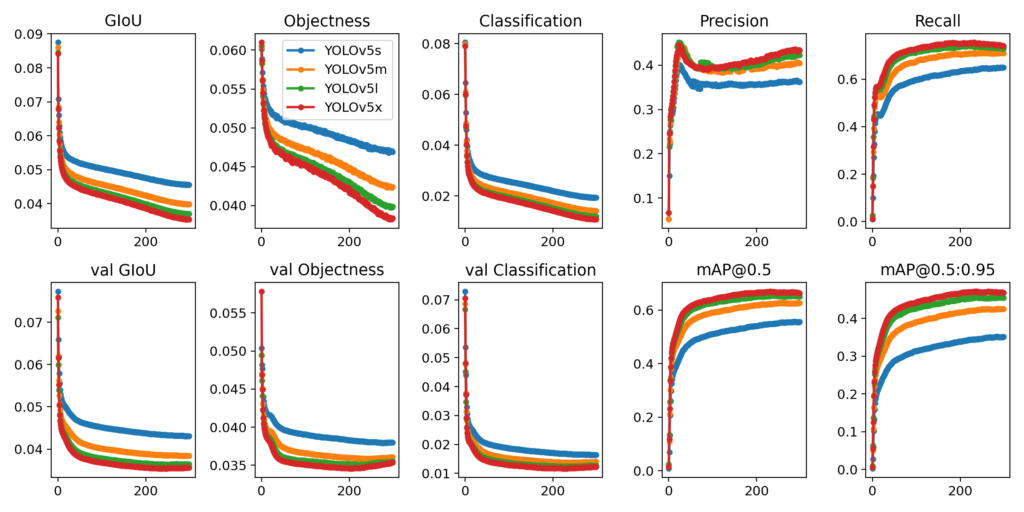
全体的にみてYOLOv5sとYOLOv5mの間には明確な差がありますが、YOLOv5mとYOLOv5l / YOLOv5xの間にはそれほどの差がないようです。
事前トレーニング済みモデルは以下のGitHubからダウンロードすることができます。
train.py 実行時のオプション –weights yolov5m.pt で指定することもできます。
他にも –weights ” –cfg models/yolov5m.yaml でも指定することができます。
各 yolov5◯.yml のパラメータの違いです。
| パラメータ | yolov5s | yolov5m | yolov5l | yolov5x |
| depth_multiple (モデルの深さ) | 0.33 | 0.67 | 1.0 | 1.33 |
| width_multiple (モデルのチャンネル数[幅]) | 0.50 | 0.75 | 1.0 | 1.25 |
学習の実行
いよいよ学習モデルの作成です。
今回は学習の反復回数(epochs)を200回に設定して実行しました。
python3 train.py --data data/data.yaml --weights yolov5m.pt --epochs 200実行環境によっては、学習途中でメモリーリークなどで中断してしまうこともあります。
その時は –batch-size オプションを調整してみてください、既定値は16ですのでそれより小さな数字を入れると時間はかかりますが最後まで学習が続行される可能性があります。
ちなみに、Corei5-2400(グラボ無し)で実行したときは以下のオプションでなんとか最後まで実行できました。
python3 train.py --data data/data.yaml --weights yolov5m.pt --batch-size 4 --epochs 200train.py の主なオプションの説明
https://github.com/ultralytics/yolov5/blob/fad57c29cd27c0fcbc0038b7b7312b9b6ef922a8/train.py#L428
https://github.com/ultralytics/yolov5/blob/fad57c29cd27c0fcbc0038b7b7312b9b6ef922a8/train.py#L428| オプション | 説明 | 既定値 |
| data | 学習パラメータファイルへのパス | |
| weight | 事前トレーニング済モデルの指定 | yolov5s.pt |
| epochs | 学習の反復回数 | 300 |
| batch | バッチサイズの指定 -1 を指定すると最適なバッチサイズ(AutoBatch)で実行されます | 16 |
| img | 学習画像のサイズを指定 | 640 |
| name | 学習結果の保存先ディレクトリ | exp |
| patience | 学習精度が指定回数改善されない場合、学習を早期停止します | 30 |
学習実行結果
学習が終了すると、学習モデルの評価のサマリが表示されます。
200 epochs completed in 0.310 hours.
Optimizer stripped from runs/train/exp/weights/last.pt, 42.2MB
Optimizer stripped from runs/train/exp/weights/best.pt, 42.2MB
Validating runs/train/exp/weights/best.pt...
Fusing layers...
Model summary: 212 layers, 20869098 parameters, 0 gradients, 47.9 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 2/2 [00:00<00:00, 3.94it/s]
all 52 119 0.992 0.994 0.995 0.958
EF210-100 52 26 0.999 1 0.995 0.961
KOKI107-FL 52 28 1 0.972 0.995 0.948
KOKI107-ICon 52 19 0.994 1 0.995 0.962
KOKI104-YAMATO 52 24 1 1 0.995 0.964
TAKI1000-NiSeki 52 22 0.967 1 0.995 0.955
Results saved to runs/train/exp論理的にはP , R , mAP50 , mAP50-95 が1に近ければ優秀な学習モデルといえますが、過学習による検出判断の硬直化や誤検知も発生するので、学習曲線や実際の検出精度などで Epochを調整する必要があります。
学習実行結果は yolov5/runs/train/exp ディレクトリに保存されます。
exp ディレクトリは存在すると exp2 exp3・・・ と作られていきます。
学習モデルは yolov5/runs/train/exp/weights ディレクトリに保存されます。
best.pt は学習で最も良い評価の学習モデルです。last.ptは最後の学習結果の学習モデルです。
- ホーム
- yolov5
- runs
- exp — 学習実行結果
- results.png — 学習経過の評価グラフ
- results.csv — 学習経過の評価データ
- opt.yaml — 学習実行時のオプション一覧
- train_batch0.jpg — 学習データからサンプリングされたミニバッチ
- val_batch0_labels.jpg — 検証データからサンプリングされたミニバッチ
- val_batch0_pred.jpg — 検証データのミニバッチに物体検出実行検証結果
- weight — 学習モデル
- best.pt — 最も良い評価の学習モデル
- last.pt — 最後の学習モデル
- exp — 学習実行結果
- runs
- yolov5
学習の早期停止(Early Stopping)
過学習を防止するため、オプション –patience によって指定された回数学習に改善が見られない場合に、学習を早期停止します。
Stopping training early as no improvement observed in last 100 epochs. Best results observed at epoch 805, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.このメッセージは、早期停止(early stopping)が実行され、最後の100エポックで性能の改善が見られなかったため、トレーニングが早期に停止されたことを示しています。最も優れた結果がエポック805で得られ、その時点のモデルが best.pt として保存されました。
実行結果 exp ディレクトリのファイルの一部を紹介します
学習モデルの学習経過の評価を示すグラフ ( results.png )
過学習により検出精度が落ちていないか等がわかります。
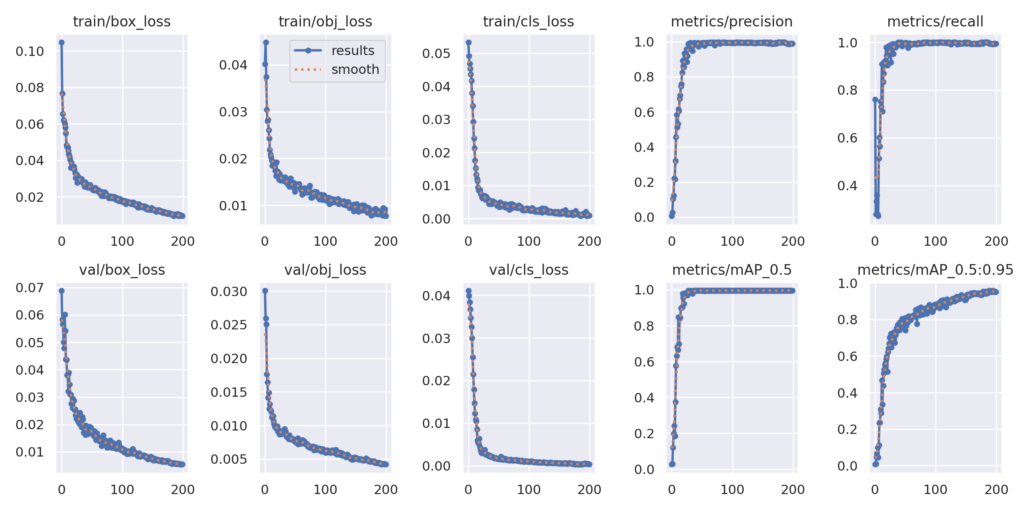
学習データからサンプリングされたミニバッチ ( train_batch0.jpg )

検証データのミニバッチに対して物体検出を実行した検証結果 ( val_batch0_pred.jpg )

独自に作成した学習モデルを使って物体検出をおこなう。
Nゲージ鉄道模型の学習データを使って作成した学習モデルを使って、実際に物体検出をおこなってみましょう。
データを以下のように配置しています。
学習モデルは best.pt を使用します。
- ホーム
- yolov5
- data
- detect — 検出対象データ
- runs
- detect
- exp — 検出結果
- train
- weights
- best.pt — 学習モデル
- weights
- detect
- data
- yolov5
yolov5/data/detect ディレクトリに検出(推論)対象となるデータをコピーします。
yolov5/runs/train/weights ディレクトリに学習モデルをコピーします。
検出対象データには、jpgファイルとmp4動画を数本入れています。






物体検出の実行
学習モデルを指定して物体検出を実行します。
python3 detect.py --source data/detect --img 1280 --weights runs/train/weights/best.ptdetect.py の主なオプションの説明
https://github.com/ultralytics/yolov5/blob/fad57c29cd27c0fcbc0038b7b7312b9b6ef922a8/detect.py#L248
https://github.com/ultralytics/yolov5/blob/fad57c29cd27c0fcbc0038b7b7312b9b6ef922a8/detect.py#L248| オプション | 説明 | 既定値 |
| source | 検出(推論)対象画像が格納されたディレクトリ | data/images |
| img | 検出(推論)対象画像のサイズ | 640 |
| weights | 学習モデル | yolov5s.pt |
| conf | 検出被写体(クラス)検出信頼度の閾値 | 0.25 |
| save-crop | 検出座標でトリミングしたものを保存 | false |
| device | 使用プロセッサ |
物体検出の実行結果
検証結果は yolov5/runs/detect/exp に保存されます。
exp ディレクトリは存在すると exp2 exp3・・・ と作られていきます。






画像に関しては、ほぼ問題ないですが一部呉検出しています。
「KOKI107-FL」が半分だけしか検出されていません。
動画の物体検知してみました
誤検知がありますが、Nゲージ鉄道模型の車種を検知しています。
物体検知精度をあげるにはどうするかを検証してみます
物体検知の精度を上げるには、
- 事前トレーニングモデルを精度の高いモデルを使用する
- 学習回数を増やす
- 学習データのかさ増し
の方法があります。
1. 事前トレーニングモデルを精度の高いモデルを使用する
事前トレーニングモデルを精度の高いモデルを使用と物体検知精度は上がります。
ハードウェアのリソースや実行速度などを勘案の上、どの事前トレーニングモデルを使うかを決定します。
同じ学習回数でも yolov5m.pt と yolov5m6.pt では精度に違いが出ます。
以下は学習回数 200 Epochs で学習したモデルを使用しています。

事前トレーニングモデルの精度を上げることにより精度を高めることができます。
2. 学習回数を増やす
学習回数増やせば物体検知精度を高めることができますが、闇雲に学習回数を増やしたからといって無限に精度が上がるわけではありません。
学習モデルが過学習してしまうと、学習データにはよく適合しますが、汎用化性能が低下してAIの得意とする学習データと似ているデータの検知判断が硬直化してしまい、検出できるはずができない事象が発生します。
精度の高いトレーニングモデル程過学習しやすくなります。
学習データをかさ増しすことで、汎用性を上げることもできます。
-
学習不足による誤検知
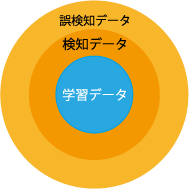
適正な学習で適正な検知判断

過学習で検知判断が硬直化

事前トレーニングモデルを yolov5m に設定して、学習回数を変えた学習モデルを使って、物体検知した結果です。
事前トレーニングモデル( yplov5m )の検出精度に限界があるようで、600 Epochs 以上は物体検出の精度が下がっているようです。400 Epochsで信用度に閾値を設けて( –conf 0.55 とか )誤検知ノイズを除去するのが現実的であるのかもしれません。
事前トレーニングモデルを yolov5m6 に設定して 400 Epochs すると。
検出精度も上がり、誤検知によるノイズもなくなりました。
3. 学習データのかさ増し
学習データの枚数を増やすのもそうですが、学習データにノイズを入れたり背景を変えたりなどの、学習データにバリエーションを持たせることも検出精度をあげることになります。



参考データ
学習モデル作成結果 (train.py)
Class : All
Weights : yolov5m.pt
| Epoch | P | R | mAP50 | mAP50-95 | hours |
|---|---|---|---|---|---|
| 50 | 0.994 | 1 | 0.995 | 0.9 | 0.079 |
| 100 | 0.996 | 1 | 0.995 | 0.929 | 0.155 |
| 150 | 0.994 | 0.999 | 0.995 | 0.951 | 0.232 |
| 200 | 0.992 | 0.994 | 0.995 | 0.958 | 0.310 |
| 300 | 0.996 | 1 | 0.995 | 0.981 | 0.462 |
| 400 | 0.997 | 1 | 0.995 | 0.984 | 0.615 |
| 500 | 0.997 | 1 | 0.995 | 0.989 | 0.768 |
| 600 | 0.997 | 1 | 0.995 | 0.991 | 0.921 |
| 700 | 0.997 | 1 | 0.995 | 0.992 | 1.172(*1) |
| 800 | 0.997 | 1 | 0.995 | 0.995 | 1.223 |
| 926(*2) | 0.998 | 1 | 0.995 | 0.993 | 1.566 |
| 1200 | 0.997 | 1 | 0.995 | 0.994 | 1.832 |
Weights : yolov5l.pt
| Epoch | P | R | mAP50 | mAP50-95 | hours |
|---|---|---|---|---|---|
| 200 | 0.997 | 1 | 0.995 | 0.973 | 0.505 |
| 300 | 0.997 | 1 | 0.995 | 0.986 | 0.754 |
Weights : yolov5x.pt
AutoBatch: Using batch-size 9 for CUDA:0 9.19G/11.75G (78%) (*3)
| Epoch | P | R | mAP50 | mAP50-95 | hours |
|---|---|---|---|---|---|
| 200 | 0.997 | 1 | 0.995 | 0.969 | 0.999 |
Weights : yolov5m6.pt
| Epoch | P | R | mAP50 | mAP50-95 | hours |
|---|---|---|---|---|---|
| 50 | 0.996 | 0.989 | 0.995 | 0.881 | 0.090 |
| 100 | 0.996 | 0.994 | 0.995 | 0.935 | 0.175 |
| 150 | 0.993 | 0.999 | 0.995 | 0.947 | 0.259 |
| 200 | 0.993 | 0.994 | 0.995 | 0.963 | 0.344 |
| 300 | 0.996 | 1 | 0.995 | 0.977 | 0.512 |
| 400 | 0.996 | 0.998 | 0.995 | 0.98 | 0.682 |
| 500 | 0.995 | 1 | 0.995 | 0.987 | 0.850 |
| 600 | 0.996 | 1 | 0.995 | 0.99 | 1.020 |
| 805(*2) | 0.997 | 1 | 0.995 | 0.99 | 1.530 |
| 1200 | 0.996 | 1 | 0.995 | 0.993 | 2.032 |
Weights : yolov5l6.pt
| Epoch | P | R | mAP50 | mAP50-95 | hours |
|---|---|---|---|---|---|
| 200 | 0.996 | 1 | 0.995 | 0.972 | 0.560 |
Weights : yolov5x.pt
AutoBatch: Using batch-size 7 for CUDA:0 9.29G/11.75G (79%) (*3)
| Epoch | P | R | mAP50 | mAP50-95 | hours |
|---|---|---|---|---|---|
| 200 | 0.997 | 1 | 0.995 | 0.973 | 1.097 |
(*1) バックグラウンドで他の処理ありのため影響が出ている可能性があります。
(*2) EarlyStopping(patience=100)で早期停止。
(*3) オプション –batch -1 を使用して AutoBatch で実行しています。
物体検出実行結果 (detect.py)
Speed: 0.4ms pre-process, XX.Xms inference, 0.8ms NMS per image at shape (1, 3, 1280, 1280)
| Weight | inference | 対yolov5m比 |
|---|---|---|
| yolov5m | 22.5ms | 1.00 |
| yolov5l | 40.2ms | 1.79 |
| yolov5x | 72.7ms | 3.23 |
| yolov5m6 | 23.8ms | 1.05 |
| yolov5l6 | 42.4ms | 1.88 |
| yolov5x6 | 78.9ms | 3.50 |
学習モデルサイズ (best.pt)
| Weight | 学習モデルサイズ | 対yolov5m比 |
|---|---|---|
| yolov5m | 42.2 MB | 1.00 |
| yolov5l | 92.8 MB | 2.18 |
| yolov5x | 173.1 MB | 4.10 |
| yolov5m6 | 71.1 MB | 1.68 |
| yolov5l6 | 153.0 MB | 3.63 |
| yolov5x6 | 280.9 MB | 6.66 |