前置き

前回はAIを使っての物体検出をYOLOv5を使って、独自の学習モデルを作って検出するところまでをやってみました。
AIの世界に触れて、今までにない衝撃を受けました。
学習データさえ揃えることができれば、高度な物体検出ができるなんて夢のような世界です。
この物体検出の機能をAIの力無しで作成しようとすれば、とんでもない労力を注ぎ込まなければなりません。
実現できたとしても、汎用性に関しては絶望的なシステムになってしまうのは明らかです。
先人のご苦労には頭が下がります。
今回は、前回使ったYOLOv5の後継YOLOv8を使ってより理解を深めていきたいと思います。
今回はちょっとしたPythonのコードを書かないといけないのですが、Python初心者というか使ったことすらないので、非常に稚拙なPythonコードが出てくるとおもいますがご容赦のほどお願い致します。
実行環境
CPU : AMD Ryzen 7 5700X BOX
メモリー:64GB (32GB x 2)
グラフィックボード:MSI GeForce RTX 3060 12GB
マザーボード:MSI MAG B550 TOMAHAWK
SSD: ADATA M.2 2TB
OS: Ubuntu 22.04
現時点でコスパの優れているAMD Ryzen7 5700Xを中心に組んでいるので、程々の性能ですが業務使用サーバーとしては充分な性能です。
YOLOv8について
YOLOv8は、YOLOv5を作成したUltralytics社が2023年1月に発表したバージョンです。
ライセンスはAGPL-3.0 (GNU Affero General Public License v3.0)となっています。
GitHub https://github.com/ultralytics/ultralytics
YOLOの系譜
- YOLOv1 ※Joseph Redmon
- YOLOv2
- YOLOv3 ※Joseph Redmon, Ali Farhadi
- YOLOv4 ※Alexey Bochkovskiy
- YOLOv7
- YOLOv5 ※Glenn Jocher(Ultralytics社)
- YOLOv8
- YOLOv4 ※Alexey Bochkovskiy
- YOLOv3 ※Joseph Redmon, Ali Farhadi
- YOLOv2
- YOLOv6 ※Meituan Technical Team
| 作者 | バージョン | バージョン |
| Alexey Bochkovskiy | YOLOv4 (2020年4月) https://github.com/AlexeyAB/darknet | YOLOv7 (2022年7月) https://github.com/WongKinYiu/yolov7 |
| Glenn Jocher (Ultralytics社) | YOLOv5 (2020年6月) https://github.com/ultralytics/yolov5 | YOLOv8 (2023年1月) https://github.com/ultralytics/ultralytics |
| Meituan Technical Team | YOLOv6 (2022年6月) https://github.com/meituan/YOLOv6 |
YOLOv8のインストール
YOLOv8のインストールについては ultralytics の Quickstart を参照してください。
CUDAのインストールについては「AIを使っての画像認識による物体検出をYOLOv5を使ってやってみた」でも説明していますので参考にしてください。
今回は pip でインストールしました。
pip install ultralyticsultralytics ディレクトリが作成されます
動作確認
cd ultralytics
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'ホーム/ultralytics/runs/detect/predict ディレクトリに bus.jpg が作成されます。
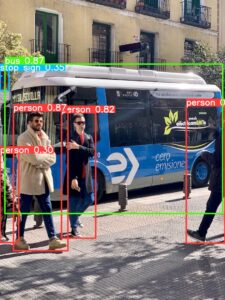
物体検知されていればOKです。
YOLOv8では、Pythonから利用する方法と、CLI(コマンドラインインターフェイス) YOLO を使用する方法があります。先程使ったコマンドはCLIを使った方法です。
Pythonでは以下のようになります。
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model('https://ultralytics.com/images/bus.jpg')YOLOv8の物体検知
YOLOv8には5種類の物体検知があります。
- 分類 (Classify)
画像を異なるカテゴリーに分類する - 検出 (Detect)
画像やビデオフレーム内のオブジェクトを検出 - セグメンテーション (Segment)
画像の内容に基づいて画像を異なる領域に分割 - 追跡 (Track)
ビデオ内のオブジェクトを追跡 - ポーズ推定 (Pose)
画像やビデオフレーム内の特定の点を検出
動きやポーズ推定を追跡するために使用
検出と追跡とポーズ推定についてみていきます。
検出 (Detect)
YOLOの基本的な機能です。
事前トレーニングされたモデルは以下にあります。
以下のように配置しました。
- ホーム
- ultralytics
- detect.py
- data
- detect
- img01.jpg ← 検出対象画像
- detect
- model
- yolov8x.pt ← 事前トレーニングモデル
- ultralytics
from ultralytics import YOLO
model = YOLO(model="./model/yolov8x.pt")
results = model.predict("./data/detect/img01.jpg", line_width=1)コマンドラインで実行します。
cd ultralytics
python3 detect.pyホーム/ultralytics/runs/detect/predict ディレクトリに im01.jpg が作成されます。

検出結果の利用
検出結果をプログラム的に利用してみましょう。
検出 model.predict で返される値を表示してみます。
まずは、検出された物体の数と座標を表示してみます。
検出結果は必要ないのでファイルへの書き出しはせずに画面に表示して、キーが押されたら終了します。
import cv2
from ultralytics import YOLO
model = YOLO(model="./model/yolov8x.pt")
results = model.predict("./data/detect/img01.jpg", show=False, save=False, imgsz=1280, line_width=1)
print("---START---")
for res in results:
path = res.path
print("-----")
print(f"Number of boxes = {len(res.boxes)}")
for box in res.boxes:
pos = box.xywh[0]
print("-----")
print(f"position = X:{pos[0].item()} Y:{pos[1].item()} width:{pos[2].item()} height:{pos[3].item()}")
annotated_frame = res.plot(line_width=1)
cv2.imshow(path, annotated_frame)
cv2.waitKey()
cv2.destroyAllWindows()
print("---END---")表示結果です。
---START---
-----
Number of boxes = 4
-----
position = X:233.68064880371094 Y:426.07696533203125 width:321.9272155761719 height:210.66064453125
-----
position = X:1148.678955078125 Y:472.454833984375 width:261.59527587890625 height:246.7529296875
-----
position = X:589.0326538085938 Y:439.0316162109375 width:348.3096923828125 height:177.603515625
-----
position = X:444.33538818359375 Y:280.07476806640625 width:144.342529296875 height:119.11346435546875
---END---次に検知対象のクラス名と信頼度を表示してクラスごとに集計します。
import cv2
from ultralytics import YOLO
model = YOLO(model="./model/yolov8x.pt")
results = model.predict("./data/detect/img01.jpg", show=False, save=False, imgsz=1280, line_width=1)
print("---START---")
for res in results: # 検知対象の数だけLoop
path = res.path
print("-----")
print(res.names)
print("-----")
print(f"Number of boxes = {len(res.boxes)}")
clscount = [0] * len(res.names) # クラスの集計配列
for box in res.boxes:
conf = box.conf[0].item() # 信頼度
cls = int(box.cls[0].item()) # クラス
clscount[cls] += 1 # クラスごとのカウント
clsnm = res.names[cls] # クラス名
pos = box.xywh[0] # 座標
print("-----")
print(f"class = {cls}:{clsnm}") # クラス表示
print(f"conf = {conf:.5f}") # 信頼度表示
print(f"position = X:{pos[0].item()} Y:{pos[1].item()} width:{pos[2].item()} height:{pos[3].item()}") # 座標表示
print("---Class Count---")
ac = 0
for i, cnt in enumerate(clscount):
if cnt > 0:
print(f"{res.names[i]} : {cnt}")
ac += cnt
print(f"Total : {ac}")
annotated_frame = res.plot(line_width=1)
cv2.imshow(path, annotated_frame)
cv2.waitKey()
cv2.destroyAllWindows()
print("---END---")実行結果です
---START---
-----
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
-----
Number of boxes = 4
-----
class = 22:zebra
conf = 0.97176
position = X:233.68064880371094 Y:426.07696533203125 width:321.9272155761719 height:210.66064453125
-----
class = 22:zebra
conf = 0.95701
position = X:1148.678955078125 Y:472.454833984375 width:261.59527587890625 height:246.7529296875
-----
class = 22:zebra
conf = 0.94071
position = X:589.0326538085938 Y:439.0316162109375 width:348.3096923828125 height:177.603515625
-----
class = 20:elephant
conf = 0.93777
position = X:444.33538818359375 Y:280.07476806640625 width:144.342529296875 height:119.11346435546875
---Class Count---
elephant : 1
zebra : 3
Total : 4
---END---実行結果の返り値 results
こんな様な感じですね。
- results
- names クラス名タプル
- path ソース・ファイルのパス
- boxes 検知対象
- cls クラス番号
- conf 信頼度
- xyxy 検知対象座標 xyxyフォーマット
- xywh 検知対象座標 xywhフォーマット
おまけ
どのあたりまで使えるかちょっと遊んでみました。
フリー素材の動画から人物だけを検知してみました。
YOLOv5よりも早くて精度も高いようです。
といっても、4K画質のmp4画像20秒で1分掛かりますけどね。
追跡 (Track)
追跡 (Track) は動画で検知した対象にIDを付与して追跡する機能です。
Results の Boxes にIDが追加されて出力されます。
事前トレーニングモデルは検出(Detect)と同じものを使っています。
以下のように配置しました。
- ホーム
- ultralytics
- track.py
- data
- track
- m01.mp4 ← 検出対象画像
- track
- model
- yolov8x.pt ← 事前トレーニングモデル
- ultralytics
from ultralytics import YOLO
# トラッキングパラメーターを構成し、トラッカーを実行
model = YOLO('./model/yolov8x.pt')
results = model.track(source="./data/track/m01.mp4", conf=0.05, show=False, save=True, imgsz=1280, line_width=1)実行結果です。
検知対象ごとにIDが付けられて追跡することができています。
ポーズ推定 (Pose)
画像やビデオフレーム内の特定の点を検出して、動きやポーズ推定を追跡するために使用します。
各点はキーポイントとして座標がセットされます。
事前トレーニングされたモデルは以下にあります。
以下のように配置しました。
- ホーム
- ultralytics
- pose.py
- data
- pose
- p01.mov ← 検出対象画像
- pose
- model
- yolov8x-pose.pt ← 事前トレーニングモデル
- ultralytics
from ultralytics import YOLO
model = YOLO('./model/yolov8x-pose.pt')
results = model('./data/pose/p01.mov', show=False, save=True,conf=0.5, imgsz=1280, show_labels=False, show_boxes=False)実行結果です。
実行結果からキーポイントを取り出してみましょう。
動画だと結果がわかりにくいので、jpg画像で実行します。
import cv2
from ultralytics import YOLO
keypoint_class = ( "nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle" )
model = YOLO('./model/yolov8x-pose.pt')
results = model('./data/pose/img02.jpg', show=False, save=False, imgsz=1280, show_boxes=False)
for res in results: # 検知対象の数だけLoop
path = res.path
i=0
print(f"Number of boxes = {len(res.boxes)}")
print("-----")
for box in res.boxes:
ids = box.id
pos = box.xywh[0]
conf = box.conf[0].item()
cls = int(box.cls[0].item())
clsnm = res.names[cls]
keypoint = res.keypoints.xy[i]
i += 1
print(f"+++++ Box-{i}")
print(f"class = {cls}:{clsnm}"); # 検知アイテムのクラス
print(f"conf = {conf:.5f}"); # 検知アイテムの信頼度
print(f"id = {ids}"); # 検知アイテムのID
print(f"position = X:{pos[0].item()} Y:{pos[1].item()} width:{pos[2].item()} height:{pos[3].item()}"); # 検知アイテムのPosition
print("+++++")
kc = 0
for kp in keypoint:
kpcls = keypoint_class[kc]
print(f"{kpcls} (X={kp[0].item():.5f},Y={kp[1].item():.5f})") # キーポイントの座標
kc += 1
annotated_frame = res.plot(boxes=False)
cv2.imshow(path, annotated_frame)
cv2.waitKey()
cv2.destroyAllWindows()実行結果です。
まずは画像

出力結果です。
Number of boxes = 2
-----
+++++ Box-1
class = 0:person
conf = 0.94770
id = None
position = X:1062.0 Y:508.0 width:170.0 height:482.0
+++++
nose (X=1029.23083,Y=299.22629)
left_eye (X=1039.52698,Y=290.19904)
right_eye (X=1025.79639,Y=293.39688)
left_ear (X=1067.20764,Y=301.43704)
right_ear (X=0.00000,Y=0.00000)
left_shoulder (X=1099.48499,Y=358.70178)
right_shoulder (X=1009.18750,Y=364.36856)
left_elbow (X=1134.11963,Y=421.99258)
right_elbow (X=988.91150,Y=431.78940)
left_wrist (X=1122.85950,Y=478.12689)
right_wrist (X=990.00928,Y=482.62396)
left_hip (X=1078.52771,Y=499.19608)
right_hip (X=1020.86267,Y=502.58405)
left_knee (X=1090.10974,Y=604.24011)
right_knee (X=1037.55188,Y=605.82324)
left_ankle (X=1102.04382,Y=715.40875)
right_ankle (X=1057.71887,Y=710.79810)
+++++ Box-2
class = 0:person
conf = 0.94201
id = None
position = X:807.0 Y:536.0 width:216.0 height:422.0
+++++
nose (X=831.58649,Y=371.65469)
left_eye (X=840.82703,Y=363.89575)
right_eye (X=828.34070,Y=367.32281)
left_ear (X=864.75555,Y=374.93262)
right_ear (X=0.00000,Y=0.00000)
left_shoulder (X=884.28857,Y=430.87198)
right_shoulder (X=815.53137,Y=418.10156)
left_elbow (X=900.60437,Y=474.73282)
right_elbow (X=777.43030,Y=386.55066)
left_wrist (X=899.14191,Y=510.15015)
right_wrist (X=735.79382,Y=354.21539)
left_hip (X=874.05151,Y=536.78326)
right_hip (X=826.90509,Y=534.73206)
left_knee (X=876.10944,Y=625.61163)
right_knee (X=819.94067,Y=625.64819)
left_ankle (X=880.01257,Y=725.66827)
right_ankle (X=810.80286,Y=716.70422)各人物のキーポイントが座標でポイントされています。
まとめ
AIによる画像検知の結果を、どのように使うのかが気になったので調べてみました。
これまでは、「画像が認識されて凄い」だけだったのが、具体的に検知後のデータの扱いが見えてきました。